 Web Log Storming
Web Log Storming CD Label Designer
CD Label Designer MicroBiz Balance
MicroBiz Balance  Grocify
Grocify Agenda At Once PIM
Agenda At Once PIM Decision Oven
Decision Oven Software Development
Software Development Web Design and Programming
Web Design and Programming Examples of our Work
Examples of our Work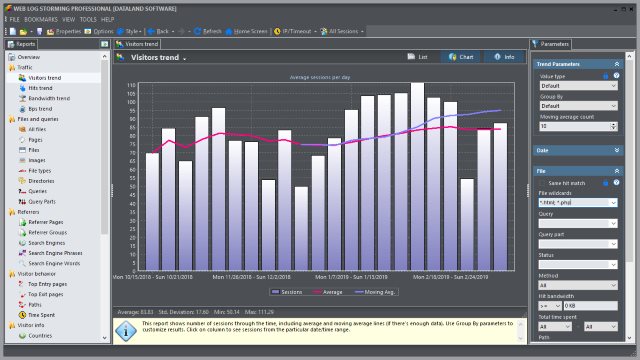





As you might know, we have released Web Log Storming v2.5 a day ago. This post is a follow up that explains few important changes.
Update Subscription
Even though we’ve switched to optional yearly update policy starting with v2.0 (as it is and was indicated on the purchase page), we have decided to prolong activating it for a while. Main reason for waiting was to give you, especially to v1.x users, some additional time to get used to the idea.
Now that time has come. Version 2.5 now informs user about date when free updates period ends (see Help | About), but it will never cease to work. Next version, however, will cease to work for those who bought their licenses more than a year ago. You’ll have three options:
- Continue using the last version that you are eligible to, forever, or until you eventually decide that improvements are beneficial enough for your needs
- Buy an update subscription for another year (for about 40% of full license price)
- Buy a lifetime update subscription (for full license price)
Of course, in case you decide to extend subscription months or years after the original one expired, your new free updates period starts from the date of the new purchase. On the other hand, if you decide to extend it before current one expires, new period will not start until the original expiration date.
Important: as version 2.5 is the last version that will be free forever for all v2.x users, we strongly suggest you to install it.
Spider detection
If you often use View | Human option, you might suddenly notice dramatically reduced number of visitors. Don’t worry, it doesn’t mean that your business is going downhill. 🙂 We’ve implemented smarter algorithm to detect which visitors / domains are behaving like spiders.
It would be easier for analysis if spiders and bots followed few simple rules: introduce themselves as such in User agent field, read and respect robots.txt file, etc. Although some do (like Google, Yahoo and similar legitimate spiders), some don’t care and/or are trying to full us in different ways (“referrer spam”, for example).
This more advanced algorithm tries to figure out if certain domains and visitors don’t behave like human beings. For example, if you get lots of hits on small number of different files from a single domain on regular basis over the time, it’s most probably a bot. Of course, exceptions are always possible (false negatives and false positives), but we think that we’ve managed to reduce mistakes significantly compared to previous version.
That said, if you notice some obvious false positive/negative, feel free to let us know. We will analyze these sessions and see what we can do to improve the detection further.
Links:



